How JavaScript Works: Engine, Runtime & Call Stack
 JavaScript
JavaScript JavaScript has become increasingly popular over the years, branching off from strictly client-side development to back-end development, hybrid application development, and more. Many developers use JavaScript daily but don't know what's going on under the hood. Having a full understanding of the technology will help you to understand how and when to use particular components, and will also help you write better applications.
In this article, we'll dig deeper by showing you how JavaScript works behind the scenes and how you can leverage it for your benefit in a multitude of application types.
The JavaScript Engine
JavaScript consists of two main components, the memory heap, and the call stack, and is a great starting point for discussing how JavaScript works.
- Memory Heap: The memory heap is where the memory allocation happens. Anytime you create variables or objects, they get stored in the memory heap, and are then accessible for use in your application or for deletion.
- Call Stack: The call stack is where your stack frames are contained as your code is executed. The call stack manages the global and function execution contexts, where new processes get queued up and ordered in the call stack as new function calls, events, and more are added.

A popular example of a JavaScript engine is Chrome V8, the engine that's shipped with the Google Chrome Browser. This engine is also used in other popular projects like Opera, NodeJS, and Couchbase.
The JavaScript Runtime
In addition to the memory heap and call stack, Web API's like the DOM (Document Object Model), AJAX (XMLHttpRequest) for making asynchronous server calls, and many more exist to further complete the JavaScript framework.
So how does the engine differ from the runtime? Although these two terms are commonly used interchangeably, they are different from each other.
The engine is responsible for providing the mechanics that allow JavaScript to run, parse, and compile data, producing machine-executable operations.
The runtime environment provides all the built-in libraries that are available to the program at execution time, like the DOM, AJAX, libraries, etc.
The JavaScript Call Stack
The Call Stack is a structure that records the current position of an executable script. Since JavaScript is a single-threaded programming language, it can only execute a single process or function at a time.
When you create a function call, that call prepended to the top of the stack. Once you return from the function, you pop off the top of the stack, meaning the process is removed from the top of the stack. Stack items are popped from the top. This process works its way downwards through the stack frame until each stack frame is empty.
Here's an example of how the call stack works:
function log(s) {
return s;
}
function output() {
var s = log("hi");
console.log(s);
}
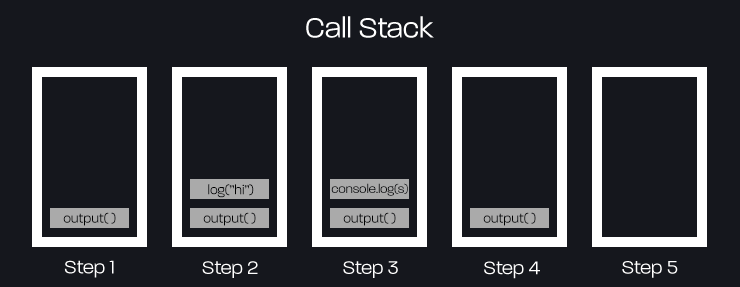
output();Here's the full description and break down of this process:
- 1. The
output()method is executed at the beginning of the script and added as the first item to the call stack. - 2. Within the
output()method, a string variable, s, is assigned the value "hi" through thelog()method. Since thelog()method is the next action performed, it is added to the top of the call stack. - 3. The value passed into the
log()method is immediately returned, removing the method, from the call stack, and adding the next action,console.log(s)to the top of the call stack. - 4.
console.log(s)is then removed from the call stack since it has executed. - 5. At this point, the script has fully executed and there is nothing remaining in the call stack.
To simplify, here is what the process looks like graphically:
What Causes a Stack Overflow?
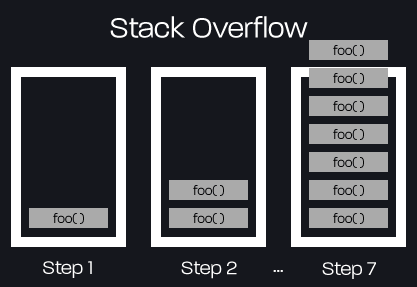
A stack overflow occurs once you've reached the maximum call stack size, typically if you're using recursion or haven't tested your code properly. Here's an example of what this could look like:
function foo() {
foo();
}
foo();Once executed, the script is now caught in an infinite loop with no termination conditions. In the call stack, the function call to foo() gets added to the top of the stack each time the function is called. Since no values are returned, the function calls get added to the stack repeatedly until the application has run out of memory, generally resulting in a browser hang up, or even a crash.
The JavaScript Event Queue
Any event that the engine receives, such as a user click event or a network response, is placed in an event queue. This is separate from the call stack and handled on a secondary basis, meaning the event queue will not be processed until all items from the call stack have been fully executed.
There may be cases where you require functions to carry on heavy tasks, such as calling a REST API to return data, or image manipulation functionality required to render the full page. The problem is the browser could remain unresponsive until the processes have completed. That's because JavaScript is synchronous. The browser will not fully render the page until all items from the call stack have been executed properly, resulting in an unresponsive browser and a bad user experience.
An example of a synchronous callback would look something like this:
function my_func(id) {
console.log(id);
}
console.log("1");
my_func("2");
console.log("3");
// output:
// 1
// 2
// 3You can get around this by using asynchronous callbacks within your JavaScript code, which prevents UI render-blocking and runs in the background until the process has completed, allowing other processes to run at the same time.
One example of an asynchronous callback could look something like this:
console.log("1");
setTimeout(function() {
console.log("2");
}, 1000);
console.log("3");
// output:
// 1
// 3
// 2In this example, each console.log() function appears that it will output in numeric order like the previous example, because they're placed in order in the code. However, the setTimeout() function is instructed to wait one second before outputting the number 2. So, the output that you actually receive is out of order, because 1 and 3 both output immediately, while 2 outputs after one second from being called.
Conclusion
This outline of the JavaScript engine, the runtime, and the call stack should give you a good idea of the bigger picture of how JavaScript works and how it can be used for optimal application performance. This could also be a good opportunity to revisit some of your older applications and optimize them for speed and performance where needed.
Written by: J. Rowe, Web Designer & Developer
Last Updated: September 08, 2020Created: August 16, 2020